基于GNIPSO-SVR的水质预测模型研究(二)
发布时间:2021-06-18 22:49
编辑者:特邀作者余秀梅
1.2支持向量回归机
支持向量回归机(Support Vector Regression, SVR)与SVM的主要不同点是寻找的一个最优超平面,不是将两类样本点分离的最远,而是让所有的样本点距离这个最优超平面的总方差最小 。若给定样本数据集{(xi,yi),i=1,2,...,n},其中xi=T,yi∈R,一个回归函数则被建立:

式(5)中,φ(x)为原始特征数据的非线性映射函数,w为权向量,b∈R为阈值。
引入线性不敏感损失函数θ,f(xi)表示预测值,yi为相对应的实际值,|yi−f(xi)|为真实值与预测值之间的差,θ不敏感函数引用的意义在于若|yi−f(xi)|在允许误差范围内,那么f(xi)没有损失,如式(6)所示。引入正则化参数c,式(5)可以转化为式(7)的代价函数:

引入松弛变量ξ1i,ξ2i,可以建立式(8)的目标函数与式(9)的约束条件:
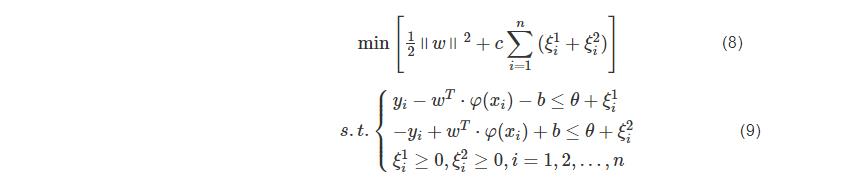
引入拉格朗日函数和核函数K(xi,xj)=φ(xi)φ(xj),可将式(8)和式(9)变换成对偶形式:
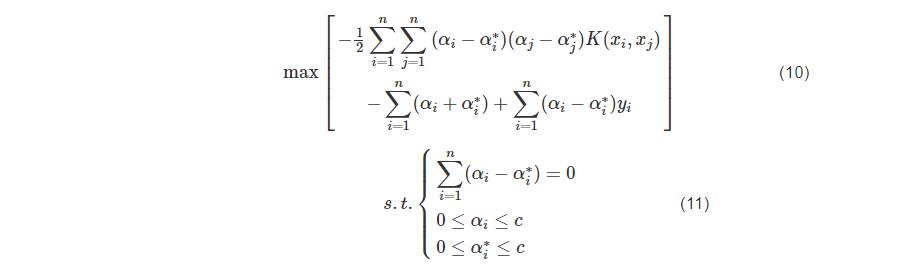
式(10)-(11)中的α为拉格朗日乘子,在KKT(Karush-Kuhn-Tucker)条件下,对最优解α和α∗求解,可以得出:
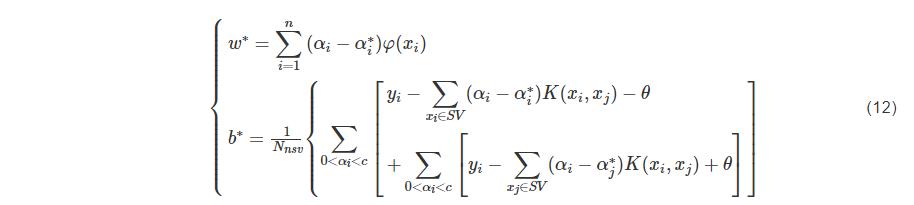
式(12)中Nnsv表示支持向量的个数,计算可得偏置量b∗。综上,最终可得SVR的拟合函数,如式(13):
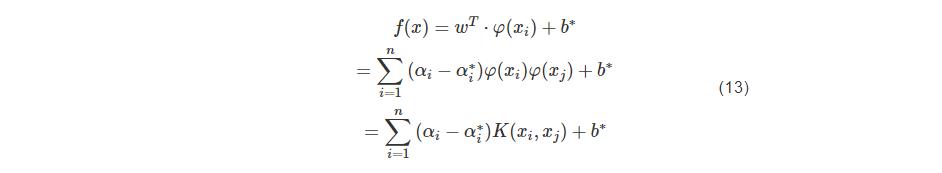
当核函数选择的是式(14)的sigmoid函数时,SVR实现的是一个多层感知器神经网络,对未知变化状况的样本集具有良好的泛化能力,溶解氧的预测值可以表示为式(15):

声明:本文所用图片、文字来源《信息与控制.北大核心CSCD》,版权归原作者所有。如涉及作品内容、版权等问题,请与本网联系删除。
相关链接:神经,溶解氧,拉格朗日



















登录后才可以评论